문자를 사용한 수 표현
- UTF-8은 문자(예:A)를 표현하는 비트들(2진수 0000000001000001)로부터
나온 숫자들(0x0041)을 표현하는 숫자들(UTF-8로 인코딩한 값)을 표현하기 위해
숫자(실제 유니코드 값 0x0041을 UTF-8로 인코딩한 0x41)들을 사용한다.
하지만 이제는 문자를 사용해 수를 표현할 수도 있다고 하네요.
컴퓨터와 컴퓨터 사이의 통신이 시작되고 사람들은 더 많은 정보를 컴퓨터 사이에 송수신하고 싶어서
2진 데이터를 전송하고 싶었다고 합니다.
하지만 2진 데이터를 직접 보내는 것은 생각처럼 단순하지 않다고해요.
아스키 코드 중 상당수가 제어문자로 예약되어 있고 이런 제어문자는 시스템에 따라 처리하는 방식이 다르고
몇몇 시스템은 7비트만 송수신할 수 있었습니다.



-
예시 1: 문자 A는 아스키 문자이며 유니코드 값은 65로, 이는 16진수 0x41(0100 0001)인데, 7비트 이내로 표현 가능하므로 UTF-8로도 0x41로 표현된다.
-
예시 2: 문자 π는 유니코드 값이 7비트를 벗어난다. 그러나 11비트 이내에 표현이 가능한 비교적 앞쪽에 위치한 문자며, 따라서 그림과 같이 2바이트에 표현이 가능 하다.
-
예시 3: 문자 한은 한글 문자로 16비트를 모두 사용한다. 마지막 16비트가 1이며 따라서 이를 표현하기 위해서는 그림과 같이 3바이트를 사용해야 한다. 참고로 유니코드에는 완성형 한글 11,172자뿐만 아니라 조합형 자모가 모두 포함되어 있으며, 이처럼 한글의 UTF-8 인코딩 값은 모두 각 문자당 3바이트를 차지한다.
-
1바이트를 차지하는 글자는 U+0000~007F 영역으로서, 아스키 코드의 127개의 문자가 있다.
-
2바이트를 차지하는 글자는 U+0080~07FF 영역으로서, 유니코드/0000~0FFF의 일부인 제어문자, 라틴어, 음성기호, 조정문자, 결합문자, 그리스어, 키릴(러시아어 등), 아르메니아어, 히브리어, 아랍어, 시리아어, 타나문자(몰디브), 은코문자(아프리카)의 1920개의 문자가 있다.
-
3바이트를 차지하는 글자는 U+0800~FFFF 영역으로서, 유니코드/0000~0FFF의 일부부터(사마리아 문자~) 유니코드/F000~FFFF까지라는 유니코드 대부분의 문자들 6만여개가 포함된다.
-
한글 조합형 자모는 U+1100~11FF[3] 영역에 위치한다.
-
한글 완성형 자모는 U+3130~318F 영역에 위치한다.
-
한글 완성형 글자는 U+AC00~D7A3[4] 영역에 위치한다. 예를 들어 '갑'의 유니코드값은 16진수 0xAC11(1010 1100 0001 0001)인데, 이는 총 16비트가 필요하므로 1110 1010 1011 0000 1001 0001 으로 표현한다
-
1) 출력 가능하게 변경한 인코딩
이 방식은 ACSII 문자가 아닌 놈들만 "=XX"(X:0~9, A~F)와 같은 모양으로 인코딩하는 방식을 말한다. 따라서 7Bit ASCII로 표현할 수 없는 문자는 한 바이트가 3바이트로 늘어난다. 따라서 이 방식은 크기가 최대 3배로 늘어날 수 있어 효율성 면에서는 최악이라 할 수 있다.
2) 베이스64 인코딩
Base64란 Binary Data를 Text로 바꾸는 Encoding(binary-to-text encoding schemes)의 하나로써 Binary Data를 Character set에 영향을 받지 않는 공통 ASCII 영역의 문자로만 이루어진 문자열로 바꾸는 Encoding이다.
Base64를 글자 그대로 직역하면 64진법이라는 뜻이다. 64진법은 컴퓨터한테 특별한데 그 이유는 64가 2의 제곱수 64=2^6이며 2의 제곱수에 기반한 진법 중 화면에 표시되는 ASCII 문자들로 표시할 수 있는 가장 큰 진법이기 때문이다. (ASCII에는 제어문자가 다수 포함되어 있기 때문에 화면에 표시되는 ASCII 문자는 128개가 되지 않는다.)
핵심은 Base64 Encoding은 Binary Data를 Text로 변경하는 Encoding이다.
변경하는 방식을 간략하게 설명하면 Binary Data를 6 bit 씩 자른 뒤 6 bit에 해당하는 문자를 아래 Base64 색인표에서 찾아 치환한다. (실제로는 Padding을 더해주는 과정이 추가된다.)


3) URL 인코딩 / 디코딩("퍼센트 인코딩"으로도 부른다.)
먼저, URL 인코딩이란 URL에서 URL로 사용할 수 없는 문자 혹은 URL로 사용할 수 있지만 의미가 왜곡될 수 있는 문자들을 '%XX'의 형태로 변환하는 것을 말한다. 여기서 XX는 16진수 값이다. 그리고 URL 디코딩이란 변환된 URL을 다시 원래의 형태로 되돌리는 것을 말한다. URL 인코딩/디코딩 과정을 그림으로 나타내면 다음과 같다. 자세한 설명은 아래에서 진행하도록 하겠다.

그렇다면 URL 인코딩/디코딩은 왜 필요한 것일까? 이것을 이해하면 왜 URL 인코딩/디코딩이 위 그림과 같이 이뤄지는지 이해할 수 있게 될 것이다. 이 질문에 대한 답은 앞서 소개한 URL 인코딩의 정의에서 찾을 수 있다.
1) 먼저, 인터넷을 통해 전송할 수 있는 문자는 오로지 ASCII 문자이기 때문이다. 따라서 ASCII 문자가 아닌 문자는 인터넷을 통해 전송할 수 있는 형태로 변환해줘야 한다. 위 그림에서 빨간색으로 표시된 '피그'라는 문자와 파란색으로 표시된 '브라더'라는 문자가 바로 그 예시이다. 한글은 ASCII 문자가 아니므로 변환이 필요하다. 그리고 이때 변환하는 규칙은 UTF-8을 따른다. UTF-8에 따르면 한글 문자 1개는 3바이트로 인코딩 된다. 따라서 '피그'는 6바이트로, '브라더'는 9바이트로 인코딩 된 모습을 볼 수 있다.
2) 다음으로, ASCII 문자라 하더라도 예약된 의미를 가지고 있는 문자의 경우, 그 문자 자체의 의미를 전달하고 싶은 경우에는 이스케이프 처리가 필요하기 때문이다. 이러한 문자의 대표적인 예시로는 '/', '&', '=' 등이 있다. '/'은 URL의 각 레벨을 구분해주는 역할을 맡고, '&'는 쿼리 파라미터들을 구분해주는 역할을 맡으며, '='은 쿼리 파리미터의 값을 지정해주는 역할을 맡는다. 이처럼 이러한 문자들은 ASCII 문자이지만 URL 내에서 특별한(예약된) 의미를 가지고 있다. 따라서 이러한 문자들을 문자 그 자체의 의미로서 전달하고 싶다면 이스케이프 처리가 필요하다. 위 그림에서 keyword라는 쿼리 파라미터의 값으로 '피그&브라더'를 보내고 싶은 경우가 바로 그 예시이다. 여기서 '&'를 이스케이프 해주지 않으면 쿼리 파라미터의 구분자로 인식이 되어 왜곡된 의미가 전달이 될 것이다. 따라서 '&'를 '%26'으로 인코딩을 하여 문자 그대로의 '&'을 전달하고자 한다는 것을 나타내야만 한다.
색을 표현하는 방법
- 숫자를 사용하는 일반적인 경우 중에는 색표현이 있다.
- 컴퓨터의 이미지는 어떻게 저장될까?
우리는 컴퓨터가 0과 1만을 사용해서 자료를 저장한다. 컴퓨터는 0과 1 외의 다른 수를 사용하지 못하므로 이미지 역시 컴퓨터에 저장을 할 때는 0과 1의 이진수를 사용해서 이미지를 저장하여야 한다.
컴퓨터 모니터나 인쇄물에서 볼 수 있는 모든 디지털 이미지들을 아주 크게 확대하면, 그림의 경계선들이 연속된 곡선이 아니라 작은 사각형들이 붙어서 사각형들이 마치 계단같이 보이는 것을 알 수 있다. 이처럼 디지털 이미지들은 더 이상 쪼개지지 않는 네모 모양의 작은 점들이 모여서 전체 그림을 만든다.
이때 이미지를 이루는 가장 작은 단위인 이 네모 모양의 작은 점들을 ‘픽셀(Pixel)’이라고 한다. 픽셀은 영어로 그림(picture)의 원소(element)라는 뜻을 갖도록 만들어진 합성어로 우리말로는 ‘화소(畵素)’라고 번역한다. 화소의 수(픽셀의 수)가 많을수록 해상도가 높은 사진(그림)을 얻을 수가 있다. 같은 면적 안에 픽셀, 즉 화소가 더 조밀하게 많이 들어 있을수록 그림이 더 선명하고 정교하기 때문이다. 예를 들어 “이 그림은 해상도가 640픽셀×480픽셀이다.”라는 말은 이 그림 속에 작은 사각형 점(즉, 화소=픽셀)이 640×480=30만 7200개 들어 있다는 뜻이 된다. 이처럼 컴퓨터는 이미지를 표현할 때도 픽셀이 없다=0, 있다=1의 이진수를 사용한다.

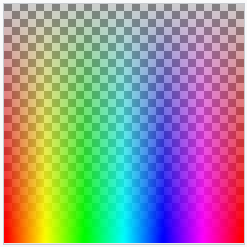
- 컴퓨터 모니터는 빨간색, 녹색, 파란색 광선을 섞어서 색을 만들어낸다. 이런 색 표현법을 RGB색 모델이라고 부른다. 손으로 그림을 그리면 가산색 시스템(빛 혼합)보다 감산색 시스템(물감 혼합)에 더 익숙할 것이다. 두시스템 모두 우리 눈이 볼 수 있는 모든 색을 만들기에는 한계가 있지만, 가산시스템(빛 혼합)이 감산 시스템(물감 혼합) 보다 더 많은 색을 만들어낼 수 있다.
1) 가산 혼합의 원리

2) RGB와 디스플레이
- RGB 가산혼합을 사용하고 있는 일반적인 사례로는 음극선관(브라운관), 액정 디스플레이, 플라스마 디스플레이와 같이 컴퓨터, 텔리비전의 영상 표시에 사용되는 디스플레이다. 화면을 구성하는 각 픽셀은 컴퓨터와 그래픽 카드 등으로 빨강, 초록, 파랑의 명도(Value)를 표현한다. 이들 수치는 감마 보정으로 표현하고 싶은 휘도에서 디스플레이에 표시되는 휘도(intensity)와 전압으로 전환되고 있다.
- 빨강, 초록, 파랑 세 종류의 광원의 조합을 통해 여러 가지 색을 표현한다. 2017년 기준으로 전형적인 디스플레이는 하나의 픽셀에 24비트 규모의 정보를 사용하고 있다. 이는 8비트를 각각 빨강, 초록, 파랑에 각각 할당함으로써 각 색상(hue)마다 256가지의 명도, 선명도를 결정한다. 이 시스템으로는 16,777,216가지(2563혹은 224)의 색상(hue), 채도(saturation), 명도(value)를 표현할 수 있다.

- 사용하지 않는 비트 8개에는 투명도 요소를 표현하기 위해 사용한다. 투명도란 해당 색을 투과해 볼수 있는 정도를 말한다.
3) 투명도 추가
- RGBA는 red green blue alpha(레드 그린 블루 알파)를 의미한다. 색 공간으로 정의되기도 하지만 실제로는 3개의 RGB색 모델에 4번째 알파 채널이 보충된 것이다. 알파는 각 화소가 얼마나 투명한지를 나타내며 알파 합성을 사용하여 이미지를 다른 이미지와 합성할 수 있게 하며, 여기에는 투명한 면과 투명 부분의 모퉁이의 안티에일리어싱 부분이 포함된다.

4) 색인코딩
- 웹 페이지는 주로 사람이 읽을 수 있는 UTF-8 문자의 시퀀스로 이뤄지는 텍스트를 표현하기 때문에, 텍스트를 사용해 색을 표현할 방법이 필요하다. URL 인코딩과 비슷한 방법으로 색을 인코딩한다.
- 웹에서 십육진수쌍으로 색을 표현하는 방법은 RGB 가산혼합에 의한 것이다. 적(red), 녹(green), 청(blue)에 해당하는 두 자리 십육진수 세 쌍으로 색깔을 나타낼 수 있다. 한 채널에 1바이트가 할당되므로 모두 3바이트의 정보로 색을 표현한다. 웹에서 색을 지정할 때에는 특수기호 #과 3쌍의 두자리 십육진수를 연속하여 사용한다.

출처 : https://namu.wiki/w/UTF-8
출처 : https://wikidocs.net/126660
출처 : https://xn--lg3bu39b.xn--mk1bu44c/9
출처 : https://en.wikipedia.org/wiki/Base64
출처 : https://it-eldorado.tistory.com/143
출처 : https://www.nise.go.kr/sedu/pt/page1_02.html
출처 : https://ko.wikipedia.org/wiki/RGBA_%EC%83%89_%EA%B3%B5%EA%B0%84
출처 : https://ko.wikipedia.org/wiki/%EC%9B%B9_%EC%83%89%EC%83%81
'웹 기술 쌈싸먹기 > 용어정리' 카테고리의 다른 글
| HTTP 구조 및 핵심 요소 (0) | 2022.01.24 |
|---|---|
| JVM, JDK, JRE? (0) | 2022.01.23 |
| 객체지향 프로그래밍(Object Oriented Programing)? (0) | 2022.01.23 |
| [웹 기술 / REST API] RESTful API 설계 가이드, REST API개념과 적용 + 코드 예제 (SpringBoot 기반) (0) | 2022.01.21 |
| JWT, API (0) | 2022.01.16 |


