계층적인 데이터구조(트리)

트리는 그 모양이 뒤집어 놓은 나무와 같다고 해서 이런 이름이 붙었습니다.

- 검정색 동그라미를 노드(node). 보통 데이터가 여기에 담긴다.
- 노드와 노드 사이를 이어주는 선을 엣지(edge) -> 노드와의 관계를 표시
- 경로(path)란 엣지로 연결된, 즉 인접한 노드들로 이뤄진 시퀀스(sequence)를 가리킵니다.
- 경로의 길이(length)는 경로에 속한 엣지의 수를 나타냅니다.
- 트리의 높이(height)는 루트노드에서 말단노드에 이르는 가장 긴 경로의 엣지 수를 가리킵니다. 트리의 특정 깊이를 가지는 노드의 집합을 레벨(level)이라 부릅니다.
- 잎새노드(leaf node)란 자식노드가 없는 노드입니다. internal node란 잎새노드를 제외한 노드를 나타냅니다. 루트노드(root node)란 부모노드가 없는 노드를 가리킵니다.
- 트리의 속성 중 가장 중요한 것이 ‘루트노드를 제외한 모든 노드는 단 하나의 부모노드만을 가진다’는 것입니다. 이 속성 때문에 트리는 다음 성질을 만족합니다.
- 임의의 노드에서 다른 노드로 가는 경로(path)는 유일하다.
- 회로(cycle)가 존재하지 않는다.
- 모든 노드는 서로 연결되어 있다.
- 엣지(edge)를 하나 자르면 트리가 두 개로 분리된다.
- 엣지(edge)의 수 |EE| 는 노드의 수 |VV|에서 1을 뺀 것과 같다.
- 트리가 아닌 예시들
회로가 존재하기 때문.


다음 예시는 트리가XXX 회로가 존재하지는 않지만 1에서 4로 가는 경로가 유일하지 않아서.

다음 예시 또한 트리가 아닙니다. 연결되지 않은 노드가 존재.

계층적인 데이터구조(2진트리)
이진트리란 자식노드가 최대 두 개인 노드들로 구성된 트리.
이진트리에는 정이진트리(full binary tree), 완전이진트리(complete binary tree), 균형이진트리(balanced binary tree)
정이진트리란? 모든 레벨에서 노드들이 꽉 채워진(=잎새노드를 제외한 모든 노드가 자식노드를 2개 가짐) 이진트리.

완전이진트리란? 마지막 레벨을 제외한 모든 레벨에서 노드들이 꽉 채워진 이진트리입니다.
정이진트리와 완전이진트리는 다음처럼 1차원 배열(array)로도 표현이 가능.


깊이 말고 left subtree와 right subtree의 노드 수를 기준으로 균형이진트리를 정의하는 경우도 있다고 합니다. 힙 정렬과 이진탐색트리는 모두 이진트리를 기반으로 만들어진 기법입니다.
트리순회
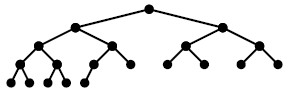
트리순회(tree traversal)란 트리의 각 노드를 체계적인 방법으로 방문하는 과정을 말합니다. 하나도 빠뜨리지 않고, 정확히 한번만 중복없이 방문해야 하는데요. 노드를 방문하는 순서에 따라 전위순회(preorder), 중위순회(inorder), 후위순회(postorder) 세 가지로 나뉩니다. 아래 트리를 예시로 각 방법 간 차이를 비교해 보겠습니다.

preorder
루트 노드에서 시작해서 노드-왼쪽 서브트리-오른쪽 서브트리 순으로 순회하는 방식. 깊이우선순회(depth-first traversal)라고도 합니다. 위 예시 트리에 전위순회 방식을 적용하면 다음과 같다.
1, 2, 4, 5, 3
inorder
루트 노드에서 시작해서 왼쪽 서브트리-노드-오른쪽 서브트리 순으로 순회하는 방식. 대칭순회(symmetric traversal)라고도 합니다. 위 예시 트리를 중위순회 방식을 적용하면 다음과 같다.
4, 2, 5, 1, 3
postorder
루트 노드에서 시작해서 왼쪽 서브트리-오른쪽 서브트리-노드 순으로 순회하는 방식. 위 예시 트리를 후위순회 방식을 적용하면 다음과 같다.
4, 5, 2, 3, 1
대용량 저장장치
( 1 ) 아이노드(inode)
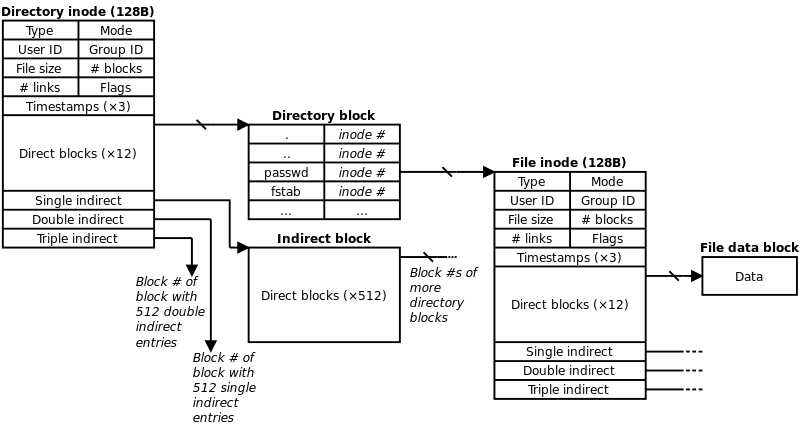
파일 시스템 내에서 파일이나 디렉토리는 고유한 inode 를 가지고 있으며 inode 번호를 통해 구분이 가능함.
사용자가 파일 또는 파일과 관련된 정보에 액세스하려고 하면 파일 이름을 사용하지만 내부적으로 파일 이름은 먼저 디렉토리 테이블에 저장된 inode 번호로 매핑됨.
그런 다음 해당 inode 번호를 통해 해당 inode 에 액세스 됨.
inode 에 포함된 정보는 아래와 같음.
- 파일 모드(퍼미션)
- 링크 수
- 소유자명
- 그룹명
- 파일 크기
- 파일 주소
- 마지막 접근 정보
- 마지막 수정 정보
- 아이노드 수정 정보
inode 포인터 구조를 통해 파일의 실제 데이터가 저장된 블록의 정보를 포함하여 파일의 메타 데이터 정보만 저장시킴.
대부분의 파일 시스템에서는 15개의 포인터로 된 데이터 구조가 저장되어 있다.
( 2 ) 심볼릭 링크(Symbolic Link)
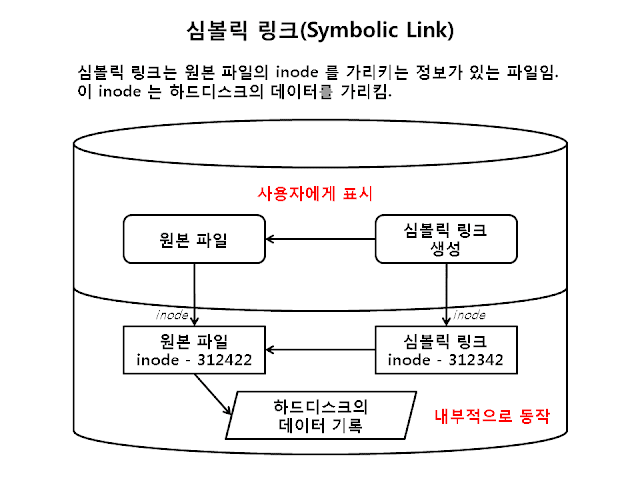
윈도우 시스템에서 제공하는 바로 가기 기능과 매우 유사함.
원본 파일에 대한 정보가 포함되어 있지 않으며 원본 파일 위치에 대한 포인터만 포함되므로 새로운 inode 를 가진 링크 파일이 생성됨
출처 : https://ratsgo.github.io/data%20structure&algorithm/2017/10/21/tree/
출처 : https://koromoon.blogspot.com/2018/05/inode-symbolic-link-hard-link.html
'웹 기술 쌈싸먹기 > 용어정리' 카테고리의 다른 글
| [입출력과 네트워킹] 저수준 I / O (0) | 2022.02.04 |
|---|---|
| [컴퓨터 아키텍처와 운영체제] 프로시저, 서브루틴, 함수, 스택 (0) | 2022.01.29 |
| HTTP 구조 및 핵심 요소 (0) | 2022.01.24 |
| JVM, JDK, JRE? (0) | 2022.01.23 |
| 객체지향 프로그래밍(Object Oriented Programing)? (0) | 2022.01.23 |


